Learn by Making Notes.
Share by Posting Notes.
Tue, Apr 19, 2016
Python开发环境的简单介绍。
依赖
import requests
当在Python代码里import一个Python module时,你就引入了一个“依赖”
搜索依赖
Python解释器需要知道依赖的位置。如果import的module不是一个built-in module,
那么Python解释器就会去sys.path指定的目录下搜索。(sys.path在不同的系统上可能会有不同的值。)
安装依赖
Python内置了Distutils,它可以帮助开发者“分发”Python module,也帮助用户安装Python module。
python setup.py install
默认情况下,上面的命令会把Python module安装类似/usr/local/lib/pythonX.Y/site-packages之类的目录。
pip
Distutils是一个比较原始的工具,Python官方也推荐用户使用第三方工具来安装Python module,比如pip。
使用pip可以方便地从PyPI上下载package,并安装它。
$ pip install SomePackage
PyPI类似于Java世界里的Maven(中央)仓库。
virtualenv
不管是Distutils还是pip,在安装时都会把package安装到一个“全局的”目录下,比如上文
提到的/usr/local/lib/pythonX.Y/site-packages。这种情况下,更新某个package的
影响是全局的;很可能导致之前的Python程序突然不能工作了。
virtualenv提供了一种解决方案,它可以给不同的Python程序提供一个隔离的环境。 一个Python程序所依赖的所有package都存在于它自己的隔离环境里。
$ virtualenv env
上面的命令生产了一个新的环境。Python执行程序,pip,和所有package都存在于env目录下。
使用-p选项,-p PYTHON_EXE, --python=PYTHON_EXE,可以在创建环境时指定Python执行程序。
Requirements Files
pip freeze > requirements.txt
pip install -r requirements.txt
pip可以把当前安装的package的版本信息“快照”下来;也就是说你可以把当前可以工作的依赖信息
“快照”下来。未来可以通过requirements.txt把所有package回滚到可工作的状态。开发者
之间也可以通过requirements.txt来确保他们的工作环境是一致的。
requirements.txt最好被提交到git仓库里。
实际上,requirements.txt有点像Ruby世界里的Gemfile.lock文件。
注: 上面的文字在某种程度上把module,package和依赖混着用。
由于本身不是专业的Python开发者,如果任何错误,恳请指正。
Tue, Mar 01, 2016

Wed, Feb 03, 2016
家里的一块卡西欧电子表没有电了,自己动手换了电池。下面是简单的步骤:
先解开手表的表带。用针或者类似的尖锐物体顶开表带的弹簧轴。这跟轴两端有弹簧,可以伸缩。

打开手表背面的盖子。 这款手表的后盖在下图的橙色圆圈所示的位置有个小的突出的部分,用小工具就可以撬开后盖。 有些手表的背部需要用专业的开表器(通过旋转)才能打开。

手表内部还盖着一个保护用的塑料盖子,用小工具轻轻揭开就可以。

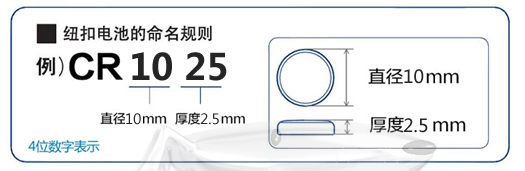
一般来说,手表电池上都有它自己的型号信息。
比如我这款手表的电池型号是Maxell SR916SW。
916是手表电池的尺寸信息,表示电池的直径是9毫米,厚度是1.6毫米。
可以去淘宝上搜索,购买一块同型号的电池。

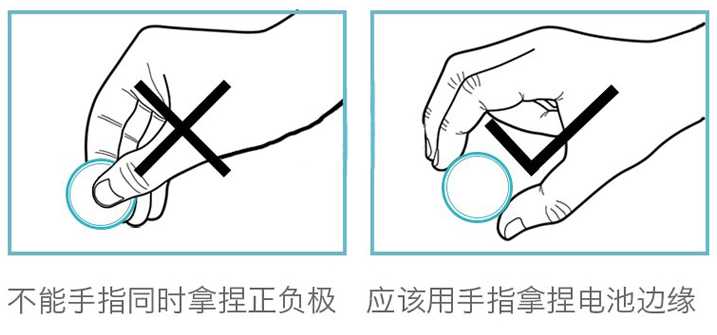
换电池的时候,因为人体会导电,不要用手指同时接触电池的正负极,而是握住电池的边缘。
换好电池后,放回后盖。 我这款手表的后盖内部有个小的缺口(第二张图的红色圆圈位置),对应于用于调整时间的表冠位置。 将这个缺口和表冠对齐,盖上后盖,缓慢地用力压紧后盖即可。
Tue, Feb 02, 2016
Safari的一个页面在占用了10多G的内存后,使得OS X系统内存耗尽,包括Safari在内很多程序卡死,变成了“未响应”的进程。 简单地在“活动监视器”里强制退出“未响应”的进程,有可能导致这些进程的数据丢失,比如Safari正在打开的页面,TextWrangle未保存的文本等。 尝试了一些方法,比如干等😅、睡眠/唤醒、关闭其它程序释放内存等,都不管用。
最后发现了一个方法,可以唤醒“未响应”的Safari进程。打开“终端”程序,在“终端”里新开一个Safari程序:
$ open -n /Applications/Safari.app/
在这个新开的Safari程序里可以正常访问之前的那个Safari程序打开的所有页面。 通过这种方法唤醒所有“未响应”的进程,保存好你的工作,然后可以在合适的时间尝试重新启动一下电脑😊。
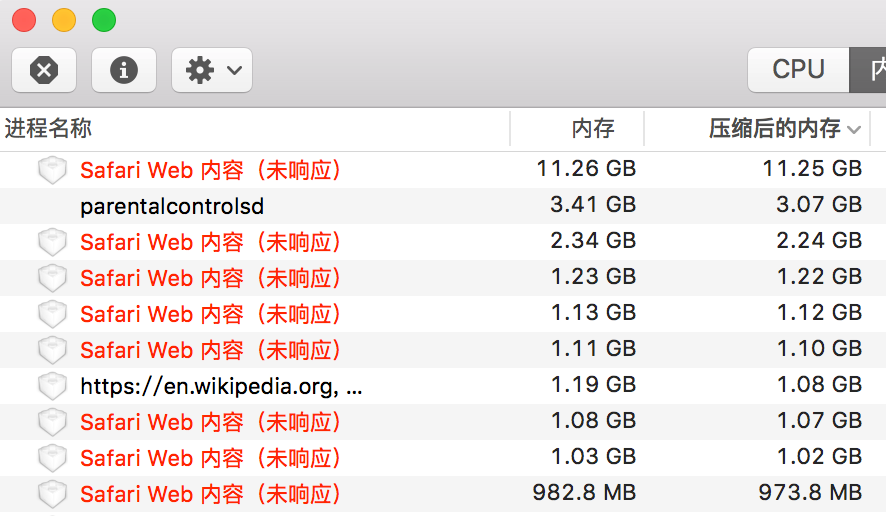
After a web page in a Safari tab eat up all memory of my OS X, the whole Safari program, along with other programs like TextWrangle, became an “not responding” process in Activity Monitor. I did not want to lose all my opening web pages in Safari and unsaved text documents in TextWrangle by simply clicking the “force quit” button in Activity Monitor. I waited a long time for my Safari to recover, sleep and wake up my OS X system, killed all other unimportant processes, but all of them did not work.
Fortunately, I found a way at last. Open the Terminal application, and open a new Safari process in the Terminal:
$ open -n /Applications/Safari.app/
And in the new opened Safari, all web pages of previous not responding Safari came to alive again. By this way, wake up all “not responding” processes, save your working in those processes, and try to restart your Mac in your very proper time.
Mon, Dec 28, 2015
Windows 7上的iTunes突然不能打开了。双击运行iTunes没有任何反应。
虽然任务管理器中显示有iTunes.exe和iTunesHelper.exe进程,但是桌面上却没有显示iTunes窗口。
反复地卸载、重装iTunes都不能解决问题。
Google了一番,在苹果官方论坛的一个帖子上找到了解决方法,
- 打开“任务管理器(Task Manager)”。
- 去“进程(Processes)”标签页,找到
APSDaemon.exe进程,然后点击“结束进程(End Prosses)”按钮。 - 关闭“任务管理器(Task Manager)”。
如果上面的步骤能解决问题,那么再修改一下Windows的启动项,防止下次启动时问题重现,
- 打开“开始”菜单,输入
MSCONFIG,回车。 - 打开“启动(StartUp)”标签页,取消勾选
Apple Push,再点击“Ok”按钮。
Tue, Dec 22, 2015
Python官网上有篇文档,Unicode HOWTO,对怎么在Python中处理Unicode做了详细的介绍。下面是这篇文档的一个简单笔记。
Unicode的相关概念
Unicode为世界上的每个字符都分配了一个数值,这个数值叫做code point。
code point通常以16进制表示,比如U+12ca,表示值为4810(16进制0x12ca)的code point。
Code point只是个整数值,而数据在计算机内部是以二进制表示的;把code point以某种方式映射成二进制数据就叫encoding。
例如一种encoding可以把每个code point表示成两个byte(虽然两个byte不能表示所有的unicode字符)。
UTF-8是一种常用的encoding,它是一种“变长”的encoding,不同的code point可能占用不同长度的byte。
UTF-8可以表示所有的code point。
Python支持近100种encoding,这里有详细的列表。
一些encoding可能有多个名字,比如utf-8,utf_8,U8,UTF,utf8都是指同一种encoding。
Python默认的encoding是ascii。默认情况下,如果Python发现字符串中的某些字符不能被ascii表示,就会抛一个UnicodeEncodeError异常。
Python中的字符串
Python里有两种类型的字符串,一种是str类型,一种是unicode类型。
两者的基类都是basestring;所以可以通过isinstance(value, basestring)来判断一个value是不是字符串。
unicode字符串
字符串可以理解成数组;unicode类型的字符串可以理解为元素为整数(code point的值)的数组。
在Python内部,unicode字符串的元素以16位或者32位整数来表示(取决于Python解释器是怎么编译的)。
构造函数unicode(string[, encoding, errors])可以用来生成unicode字符串。
它的所有参数都是8-bit strings。
>>> s = unicode('abc')
>>> type(s)
<type 'unicode'>
>>> unicode('abc' + chr(255)) # 如果参数是非8-bit strings,会报错
Traceback (most recent call last):
...
UnicodeDecodeError: 'ascii' codec can't decode byte 0xff in position 6:
ordinal not in range(128)
unichr()可以接收一个整数(code point),生成一个长度为1的unicode字符串。
ord()则接收一个长度为1的unicode字符串,返回它的code point。
>>> unichr(40960)
u'\ua000'
>>> ord(u'\ua000')
40960
unicode有着和str类似的方法。
str字符串
如果把str也视为一个数组,那么它的每个元素都是8-bit的。
(文档中有句话,“Another important method is .encode([encoding], [errors=’strict’]), which returns an 8-bit string version of the Unicode string”。
type(u'abc'.encode('utf8'))的值是<type 'str'>,所以可以推断出str是个8-bit string。)
str和unicode可以通过.encode([encoding], [errors='strict'])和.decode([encoding], [errors])函数互相转换。
>>> u = unichr(40960) + u'abcd' + unichr(1972) # 构造一个unicode字符串
>>> utf8_version = u.encode('utf-8') # unicode.encode()返回一个str对象
>>> type(utf8_version), utf8_version
(<type 'str'>, '\xea\x80\x80abcd\xde\xb4') # '\xea\x80\x80abcd\xde\xb4'的每个元素都是8 bit的
>>> u2 = utf8_version.decode('utf-8') # str.decode()返回一个unicode对象
>>> u == u2 # The two strings match
True
Python源文件和unicode
如果想在Python源文件中表示一个unicode字符串(unicode literals),可以这样,
u'abc' # 前面加个u
U'abc' # 大写的U和小写的u是等效的
u'abc\u1234' # unicode字符串的某个元素的code point可以通过“\u”来指定,“\u”后接4个16进制字符
u'abc\U12345678' # “\U”和“\u”类似,它后面接8个16进制字符
u'abc\x12' # “\x”后面接两个16进制字符
上面的方式比较繁琐。可以在Python源文件里声明源文件的encoding,然后就可以“自然语言”来声明unicode literals了。
#!/usr/bin/env python
# -*- coding: utf-8 -*- 这是Python从Emacs借鉴来的,Python实际上只去找“coding: name”或者“coding=name”,不关心“-*-”
x = u'你好' # x是长度为2的unicode对象,一个元素是“你”对应的code point,一个是“好”对应的code point
# 如果源文件没有指定coding,那么执行到这句代码时会报错
输入和输出
把输入转换为unicode,内部以unicode处理,再把unicode以某种encoding输出(比如写文件)。
如果输入输出时使用到了某些库,而这些库本身就支持unicode,那么开发时就不需要自己写unicode转换相关的代码。 比如一些XML parsers常常会返回unicode形式的数据;那么,这些XML parsers的用户就不用再去关心怎么把输入转成unicode了。
输出时,一般要先把unicode以某种方式encoding,然后再输出。
不推荐自己来做这种工作。Python有codecs库帮你做这些工作。codecs提供了open()函数,可以返回一个file-like object。
import codecs
f = codecs.open('test', encoding='utf-8', mode='w+')
f.write(u'\u4500 blah blah blah\n')
f.seek(0)
print repr(f.readline()[:1]) # 一个unicode字符可能对应多个byte,用codecs可以防止读到部分byte;比如这里的“1”,会读一个unicode字符对应的数据,而不是一个byte
f.close()
unicode和文件名
很多操作系统都支持文件名中带有任意的unicode字符。但是不同系统采用的encoding可能不太一样。
比如OS X用UTF-8,Windows支持用户配置的encoding,Unix看LANG或者LC_CTYPE环境变量。
一般来说,在Python程序中不需要关心上面这些细节。
阅读更多…Wed, Nov 25, 2015
一些小的普吉攻略。
如果想破零钱,不用去普吉机场里的汉堡王。太贵,一个简单的早餐套餐折换成人民币都要将近50元。 机场出门有个小卖部,有零食卖,可以破钱。
如果在皮皮岛只待两天的话,买一瓶驱蚊液就够了。驱蚊液在当地的便利店都有的卖的。
在皮皮岛住的酒店在岛的北部,叫“Phi Phi Natural Resort”。酒店晚上有“火”表演, 一、三、五在一家酒店门前,二、四、六在同一片沙滩的另一家酒店门前(两家酒店属于同一个老板)。
“Phi Phi Natural Resort”的菠萝炒饭要250B。沿着沙滩逆时针方向走,那边还有几个小饭店。 当地人也会在这里吃,同样的炒饭只要180B,咖喱蟹300B。 两个人一个炒饭,一个咖喱蟹就差不多了。
“Phi Phi Natural Resort”每天会提供四瓶水,足够喝了;也提供洗漱用品。 没必要从普吉本岛“背水”到皮皮岛。 本岛上的酒店也会每天提供水。
不会游泳的人在浮潜前一定要先在酒店的泳池练习,学习怎么使用浮潜工具在水里呼吸,怎么在水里保持平衡, 否则浮潜时可能有生命危险!在浮潜时鼻子是无法呼吸的,如果没有经过练习你的嘴也不会呼吸, 再加上不会游泳被直接扔到海里(非泳池浅水区),可能会很慌张很恐惧,导致呛水。 船员一般不会有耐心给你很细节的指导,也不会时刻看着你。 当时我就喝了好多海水,呛水呛到都咳血😱。
可以在迪卡侬买一对充气的、可以套在手臂上的、增加浮力的“东西”。 对于不会游泳的人,在浮潜时说不定会有用,在酒店练习的时候,可以尝试一下。
可以去迪卡侬买一双浮潜用的鞋子。海里的礁石光脚踩在上面很可能滑倒,容易摔出血。
可以买一件长袖的防晒衣,防晒的效果一流,远超防晒霜。
竹子岛和玛雅湾有400B上岛费。竹子岛一定要去,非常美。 交了上岛费后,竹子岛和玛雅湾都可以去。
“Phi Phi Natural Resort”边上有个浮潜的店,店员(一个老头)会中文。 长尾船是两小时1200B;快艇4小时7200B,可以和人拼船,最多六个人。 出海的线路,要去的岛一定要提前讲清楚、让店员写下来,出发前和船员确认好。 我们一开始和店员讲好行程里有竹子岛(也可能是我们听/理解错了),出海后船长却说行程里没有竹子岛, 要额外加钱。
阅读更多…Sat, Sep 26, 2015
InfoQ has published a nice mini book on Java garbage collection. I made a mind map from it for better understanding. (It turns out at last a mind map is not as much useful as I thought, but at least I read the mini book once more during composing the mind map.)
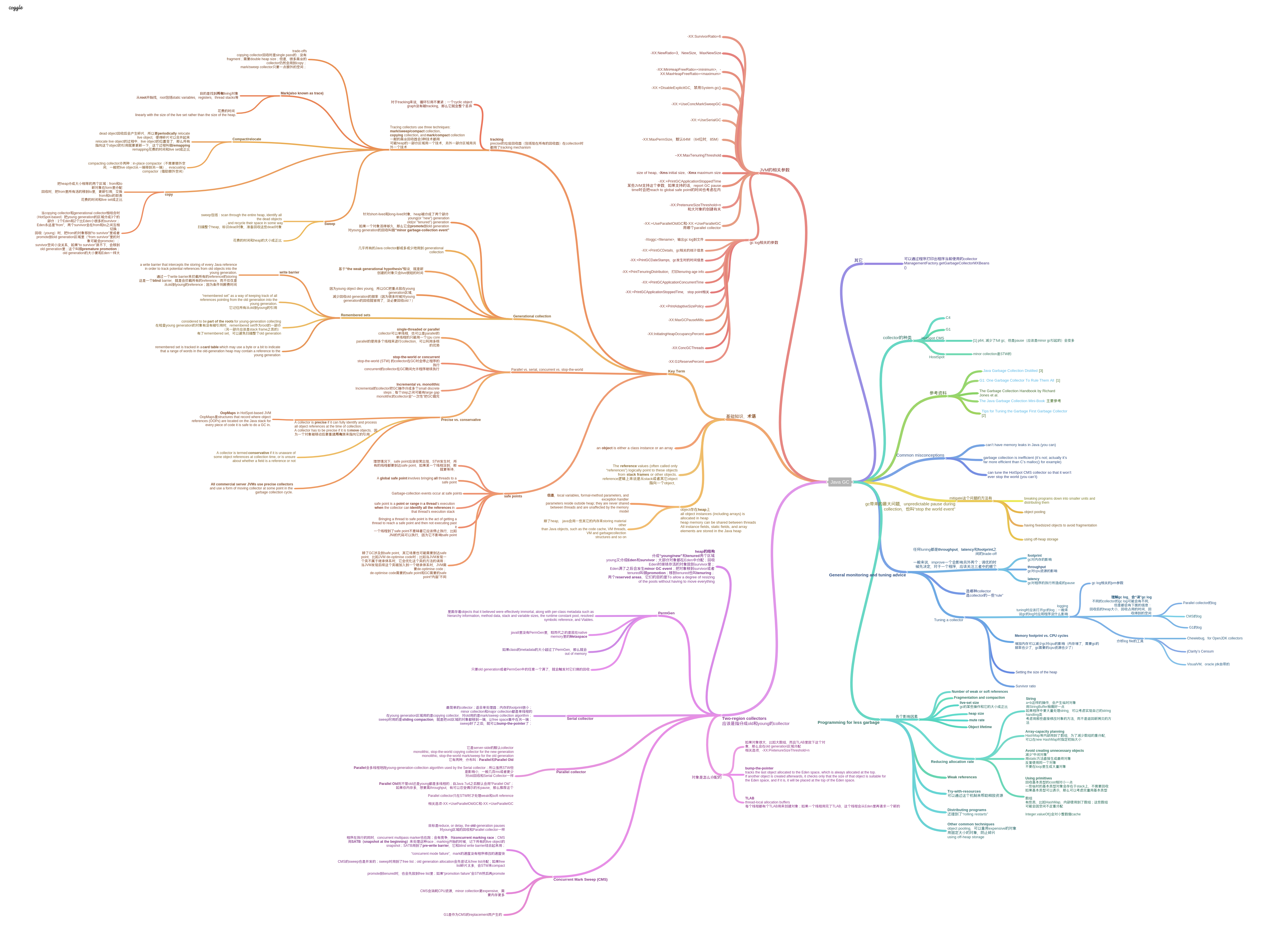
This mind map is made on coggle, a nice online mind mapping tool. The source of this mind map can be found here.
For people not working on garbage collection development, they may find the last two chapters of the mini book more useful. InfoQ also has many other articles on Java GC, they’re all worth reading.